Bootstrapping Concourse pipelines
UPDATE
Concourse 6.5.0 (2020-08-21) introduced the experimental set_pipeline step in the pipeline configuration, greatly simplifying the task. This makes this article outdated.
The problem we want to solve
Concourse is the Continuous Integration/Delivery/Deployment system that I prefer. It is so minimalistic and opinionated that it doesn’t accept at startup a pipeline configuration file, nor it is able to read a configuration file in the root of a repository like, for example, .travis.yml. You have to inject pipelines into Concourse at runtime via the fly command-line utility.
Although pipelines injected with fly are automatically stored in a Postgres database and automatically loaded when Concourse restarts, this lack of initial configuration file brings to the questions:
- How do I automatically feed it the set of pipelines that I want to be always present ?
- How do I setup in a way that all the pipelines are always automatically injected also in case of disaster (database contents lost) ?
There are various approaches that depend also on how Concourse is deployed. Concourse can be deployed automatically by BOSH or the executables can be deployed by yourself, for example using tools like Terraform starting from prepared images with tools like Packer.
This post gives an answer to the two questions above for case when Concourse is deployed without BOSH, using a two-phase bootstrap and the concourse pipeline resource.
Our requirements
- Immutable infrastructure.
- Following security best-practices, pre-generated Packer image for Concourse web contains no secrets and can be made public.
- The pre-generated images can be used by any organization: the images are generic and customizable.
- Due to the fact that the images are generic, the deployment step (for example,
terraform apply) must allow to inject custom settings, for example the location of theboostrap2.ymlpipeline. - Following security best practices, not even the deployment should inject secrets; it is better to always use a secret store like Vault.
- Again for security reason, given how Concourse is implemented, all sensitive information must arrive from a secret store, NOT from the command line of
flywith--load-vars-from=or--var=. The reason is simple: if you pass the value of the parameters fromfly, they will be kept in cleartext and will be visible to any authenticated user who issues aget-pipeline. - Adding or removing pipelines or teams must not require to rebake a Packer image or even re-deploy the same Packer image with different settings. This is obtained with a 2-phases bootstrap.
The process
We go through a two-phase bootstrap process as follows:
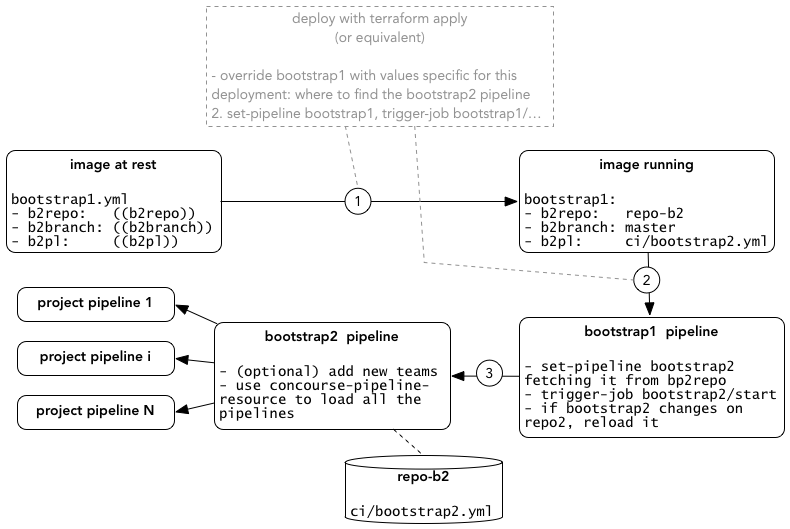
We require the bootstrap2.yml pipeline to have a first job called start. This is our API: bootstrap1 will do a trigger/job of bootstrap/start.
The branch of b2repo is master by default, but can be overridden with the b2branch parameter. This allows to develop or troubleshoot bootstrap issues (still with some care!) without impacting the master branch. In this case, the injection is done by re-deploying the concourse web image, so it still requires to operate in a staging environment.
The bootstrap2 pipeline, besides adhering to the start API, can do what is needed for the specific deployment. What we normally do is:
- Create additional teams beside
mainif needed - Configure the pipeline resource (finally the topic of this post! :-)
Sample bootstrap2 pipeline
This is a minimal configuration for bootstrap2.yml using the Concourse pipeline resource, that loads and unpauses two pipelines:
ci/foo-pipeline.ymlin repo https://example.com/user/foo.gitci/bar-pipeline.ymlin repo https://example.com/user/bar.git
resource_types:
- name: concourse-pipeline
type: docker-image
source:
repository: concourse/concourse-pipeline-resource
resources:
- name: my-pipelines
type: concourse-pipeline
source:
teams:
- name: main <1>
username: ((concourse-main-username))
password: ((concourse-main-password))
- name: foo.git <2>
type: git
source:
uri: https://example.com/user/foo.git
branch: master
paths:
- ci/*-pipeline.yml <3>
- name: bar.git <4>
type: git
source:
uri: https://example.com/user/bar.git
branch: master
paths:
- ci/*-pipeline.yml <5>
jobs:
- name: set-my-pipelines
plan:
- get: foo.git
trigger: true
params: &git-params {depth: 10}
- get: bar.git
trigger: true
params: *git-params
- put: my-pipelines
params:
pipelines:
- name: foo
unpaused: true
team: main <6>
config_file: foo.git/ci/foo-pipeline.yml <7>
- name: bar
unpaused: true
team: main
config_file: bar.git/ci/bar-pipeline.yml
- <1> Declare to the resource all the teams with associated credentials that are needed in the
putstep below. - <2> At least one git resource.
- <3> The glob expression is needed to avoid triggering the
bootstrap2pipeline on each commit to this repository! - <4> Another git resource
- <5> See (3)
- <6> Each team in this section must be declared above, see (1)
- <7> The pipeline to bootstrap, matches the glob filter at (3)
The final happy result
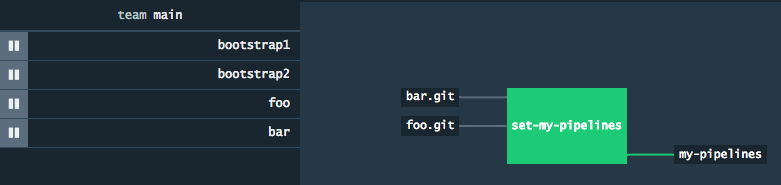
The image shows pipeline bootstrap2. On the left, pipelines foo and bar have been added by pipeline bootstrap2 using the Concourse pipeline resource.
Note that for simplicity I don’t show the optional start job, which is needed if you want to add other teams beside the default main.
Note that although currently it is a bit painful to administer multiple teams (the only way to see a given pipeline is to login it the team it belongs to), it is a good idea to keep the bootstrap pipelines in the main team and to add project pipelines in at least one separate team.
Additional notes
The secret to understand the concourse-pipeline-resource is:
- The
getstep is normally not needed; the only step that is needed is theput, since it is theputthat does afly set-pipeline. - The examples in the documentation cannot work as-is, you have to add at least one git resource on which to find the pipeline configuration file. In retrospect this sounds obvious, but I got tripped.
Another aspect that got me totally confused is the fact that this resource actually scrapes all the existing pipelines on the configured team, also the ones that are not declared in the bootstrap2 pipeline. I spent a lot of time trying to understand how the concourse-pipeline-resource could know about my other pipelines! Until I went to my trusty Concourse-in-a-box, re-did my experiments from scratch and finally saw the light. In retrospect, this is mentioned in the documentation, but in a way that wasn’t evident for me.
This is the output of the check of the my-pipelines resource:
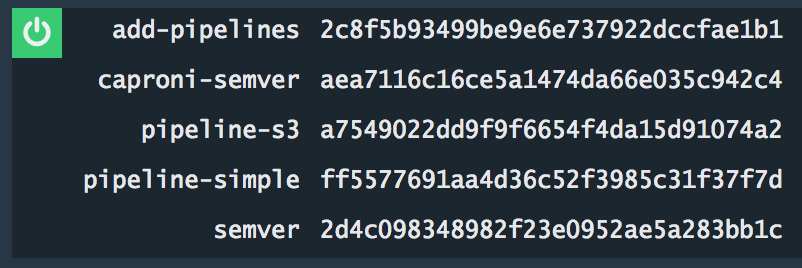
add-pipelinesis this bootstrap pipeline itselfcaproni-semveris the only pipeline I am adding with this resource and the only one I was expecting to see herepipeline-s3,pipeline-simple,semverare pipelines I added manually, whose presence here confused me
Summary
Once you understand the documentation of the concourse pipeline resource, it works perfectly and is what I use to bootstrap all my pipelines, I recommend it.